Хочу поделиться опытом по сканированию книг, как это делаю я, может кому-то информация окажется в итоге полезной.
1. ПОДГОТОВКАПрежде чем браться за сканирование книги(будем считать что сканер у вас имеется, и оцифровка будет проходить не при помощи фотоаппатара, хотя я иногда и такие фокусы откалываю - зато быстрее - книгу за минут 15 можно отщелкать. К слову, если уж было сделано фотиком - то в помощь пригодится
программа Cam to Scan для исправления фоток текста, чтобы больше походили на сканированные), нужно провести предварительную подготовку. Во первых, это касается софта(он должен быть прост в использовании, удобен, желательно бесплатен), продуманного расположения файлов(чтобы через месяц не чезать затылок куда же сканировалась книга, и как назывались файлы). Важно также аккуратно и начисто протереть стекло перед сканированием - лучше заранее избавиться от волосков и песчинок, чем потом редактировать множество файлов, уж поверьте опыту, минута протирания избавит от часа лишних редактирований! Так что если у вас длинные волосы или борода - следите чтобы стекло оставалось чистым - при массовом сканировании сотен страниц лечше выбрать такую позу, чтобы ничего не сыпалось на стекло сканера.
Итак, подготовили книгу, сканер, создали грамотную систематику для книг (у меня книги в директории "j:\!BOOKS", и далее с систематиским рубрикатором), теперь нужно выбрать программу для сканрования. Изучите свою программу на предмет массового сканирования, и если там такой функции не наблюдается(например в стандартной программе от Epson ее нет), то рекомендую потратить еще несколько минут на предварительную подготовку, которая вам в итоге сохранит часы времени.
Итак, речь идет об использовании Линукса. Проще всего скачать программу Unetbootin(мегабайт около 5 занимает), вставить флешку, и выбрать из списка любой дистрибутив Линукса! Он сам скачается и установится прямо на флешку. У меня это занимает минут 10-15. Скорость зависит от качества интернета, откуда программа скачает зачастую около 700Мб, если нормальный дистрибутив, например Дебиан или Федора. Дальше нужно просто загрузить компьютер с флешки, или SD-карты - и вы в Линуксе! Лично я пользуюсь отдельным нетбуком для этих целей, SD и Федорой. Далее вставляем в usb порт шланг сканера - и он уже готов к рабте - не нужно искать/ставить/настраивать драйвера. Достаточно запустить программу по умолчанию для сканера Simple Scan
Вот как выглядит ее интерфейс:
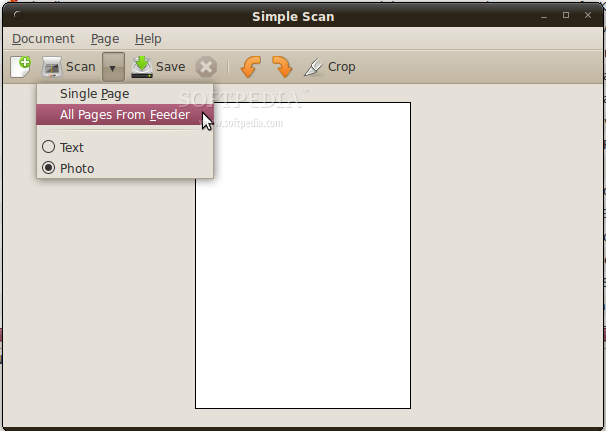
На скриншоте выбран пункт, который нам и нужен - массовое сканирование. Выбрав этот пункт сканер начнет сканировать без остановок раз за разом, нам нужно будет только успевать переворчивать страницы.
Таким образом я сканирую 50 страниц за 7 минут! Несложно посчитать что обычная 400страничная книга будет отсканирована всего за час! Это при условии максимального качества в 300dpi. А ведь при более низком качестве(150, 72) скорость будет еще быстрее, правда и качество тогда будет хуже, но если книга будет оцифровываться без изображений, и только распознаваться на OCR - этого может быть достаточно, зато даст экономию лишних 10-15 минут.
Теперь весьма прогрессивный пункт, для еще бОльшего ускорения работы - создаем виртульный диск. Визуально у нас появится отдельный диск, вроде винчестера, как диск С:\ или D:\, на самом деле данные будут храниться прямо в оперативной памяти. Это называется RAM-drive. Это непостоянное хранилище данных - после перезагрузки данные на таком диске не сохраняются(хотя есть возможность сделать автомаунт исошки, и даже автосохранение периодические и при лог-ауте, но это отдельная тема).
Итак, если у нас достаточно памяти, то часть ее можно использовать как временный диск, для обраттки изображений - т.к. файлы не будут писаться на винчестер, а будут обрабатываться прямо в памяти, то и скорость работы будет максимальной!
Из десятка протестированных и описаных мною программ для создания Рам-дисков я советую
ImDisk. Также неплохо себя показала программа
OSFMount, ведь она может работать и без установки, и как виртуальный диск, подключая iso образы дисков.
Небольшой совет - сразу запишите на такой Рам-диск портабельную версию XnView - чтобы она не стала предательски писать кеш и превьюшки изображений к себе на винчестер, тем самым погубив преимущество работы на рам-диске.
Не забудьте что создав диск вы тем самым забираете часть памяти, потому если у вас, например, 4Гб оперативной памяти, то создав 1Гб диск вы тем самым сократите себе память на гигабайт. Потому, если у вас всего 1Гб памяти - то рам-диск вам скорей всего не светит. Разве что 100-200 мегабайтный, для небольших обьемов фото к обработке.
2. ПРОГРАММЫОтсканированые страницы готовы, но их еще нужно привести к человеческому виду.
Мы можем использовать программы, предназначенные специально для этой цели: программа откорректирует размеры, разрешение, обрежет поля, поправит наклон страниц, уберет тени и артефакты. Вот две программы для этих целей:
Scan Tailor и
ScanKromsator.
Для этого наилучшим образом подходит программа XnView. Она есть для многих платформ, но версию MP лучше не использовать - ради кроссплатформенности автор пожертвовал функционалом.
Есть и другие удобные программы для работы с изображениями, есть даже Фотошоп, но для наших целей наиболее подходит именно XnView - бесплатный, легковесный и очень многофункциональный.
3. ПОВОРОТ СТРАНИЦИтак, если сканы были сделаны под 90 градусным углом - выделяем все такие файлы, и жмем Ctrl+Shift+R или Ctrl+Shift+Л для поворота всех выделенных файлов вправо или влево соответственно.
4. ОБРЕЗКАТеперь важный момент - нужно создать новую папку, например с именем 01, и туда скопировать все наши файлы - это бекап.
Переходим к обрезке. Откроем любое из изображений, и выделим часть, которая будет рабочей областью. Теперь нам надо записать координаты левой верхней точки(показывается в статусной строке при наведении мыши на нужную точку картинки). Обрезаем картинку по нашему выделению(Shift+X), и записываем кол-во пикселей по ширине и высоте.
Теперь не сохраняясь выделяем снова все файлы, жмем Ctrl+U (Tools/batch processing), и там в закладке Transformation выбираем пункт Crop, в котором вписываем запомненные координаты и размеры в нужные поля. Жмем "Go", и все 400 страниц книги у нас обрезаны и подогнаны под один размер!
Снова создаем папку, теперь с именем "02", и копируем туда результат - это еще один промежуточный бекап.
5. РЕГУЛИРОВКА КОНТРАСТА И ЯРКОСТИОткрываем один среднестатистический файл, и в меню Image/Adjust/Brightnest-Contrast устанавливаем подходящие параметры. Например по +20, как у меня зачастую оптимально получается. Запоминаем показатели, и снова выделяем все файлы, и идем в Tools/batch processing(Ctrl+U), и там в закладке Transformation выбираем пункт Brightnest и Contrast, в которых вписываем наши показатели. Нажатием "Go" все файлы будут откорректированы по яркости и контрастности.
Снова создаем папку, назвав ее "03", и копируем туда очередной бекап.
6. ТЕНЬ ОТ СГИБАТеперь открываем любой из файлов, и выделяем тень по центру по всей высоте. Переносим выделение на любой полностью белый участок изображения, и жмем Shitf+X - обрезав изображение. Сохраняем эту картинку под новым именем "сохранить как...", называем ее как-то, например "patch.jpg"
Теперь снова выделяем все файлы, снова Tools/batch processing(Ctrl+U), и там в закладке Transformation выбираем пункт "Watermark", указываем в списке наш файл patch.jpg, и в настройках ставим "по центру". Нажав Go мы применим эту "заплатку" ко всем файлам, прикрыв тень от сгиба белой заплаткой.
7. ПОПРАВКИВот и все - все файлы обработаны. Но если вдруг где-то текст съехал при сканировании, то заплатка могла налезть на текст. Потому нам могут пригодиться те самые бекапы, которые мы делали! Порой мне пригождаются бекапы даже из первой папки!
8. РАЗМЕРЫ ФАЙЛОВОтсканированная книга на 400 страниц занимает порядка 450-500Мб. Например, у меня сейчас книга на 447 страниц занимает 495Мб.
Уже на этапе обрезки размер стал 132Мб. Окончательная ПДФка высокого качества - 150Мб. Ее уже можно жать средствами ПДФ до 80Мб, или каким-нибудь ФайнРидером до 5-10Мб.
Если смотреть размеры отдельных файлов, то первичные сканы имеют размер около 1,5-2МБ, после обрезки размер уменьшается в 3 раза, и оконачтельная обработка уменьшает еще на процентов 30, то есть например 2MB / 800kb / 600kb на страницу.
9. ПРИМЕРЫ СТРАНИЦ ИЗ ВЫШЕОПИСАННОГО АЛГОРИТМА ОБРАБОТКИ
Первый столбец - это файл, каким мы его получили со сканера, 2 - обрезка, 3 - регулировка, 4 - убираем тень.
Кстати, картинка с примерами тоже делается в XnView очень просто - выделив нужные файлы жмем на создание панорамного изображения.
Если вы создавали виртуальный Рам-диск, то на пакетную обработку у вас уйдет минут 10-15. Если же обработка проходит на файлах на винчестере, или что еще хуже - на флешке, то время ожидания нужно умножить в несколько раз. Зато можно будет сходить попить чаю.
10. СОЗДАНИЕ ФАЙЛА КНИГИИтак, файлы готовы, осталось только создать саму электронную книгу.
Для DJVU все просто - идем на
официальный сайт с программами.
А вот если нужно создать pdf, то тут есть множество способов, совершенно разных - платные\
бесплатные, програмные\
онлайновые, специализированные или просто с побочной функцией. Так, к примеру, вчера я тестировал программу для конвертации видео, в которой зачем-то были также функции работы с pdf - конвертация, обьединение и разбивка.
Файнридер может сделать пдфку с картинок. Если установлен виртуальный пдф-принтер - то картинки можно послать на печать на такой принтер, и получить на выходе пдфку. Можно взять самую специализированную программу - Adobe Acrobat (не Reader!) и прямо в ней создать пдфку из картинок. Или создать файл из всех страниц при помощи бесплатной и маленькой программы IrfanView, которая, к слову, многими рассматривается как прямой конкурент XnView, на уровне как TotalCommander и FAR. Платные ломанные специализированные програмы, вроде "JPG To PDF Converter" не всегда показывают оптимальный результат.
Вопрос компрессии я не рассматриваю потому что это вопрос личный, и далеко не в каждом случае нужно терять качество ради минимизации обьема. Мак и обработку и сборку книги в альтернативных ОС(Линукс, МакОс, и т.п.) тоже пока оставлю в стороне, это совсем отдельная тема для разговора.








{kind=link}